



目标
在 Linux 上用 Miniconda 配置 PyTorch 环境
掌握
torch.nn、DataLoader、torch.no_grad()、模型保存/加载训练一个全连接网络(MLP)并在 MNIST 上达到约 97% 准确率
确保代码能在你的 CPU 和 GPU上运行
为什么使用 Miniconda?
轻量:仅几百 MB,不会像 Anaconda 那样占用 3~5 GB 磁盘空间
灵活:只安装你真正需要的包,环境干净
1. 环境配置步骤(Miniconda + PyTorch)
1.1 安装 Miniconda
参考链接。
Linux 终端执行:
# 下载 Miniconda 安装脚本(Linux x86_64)
wget -c https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
# 运行安装脚本
bash Miniconda3-latest-Linux-x86_64.sh
# 按提示操作:按 Enter 阅读协议,输入 yes 同意,默认安装路径即可,最后问是否初始化 conda 时选 yes安装完成后,关闭并重新打开终端,或执行 source ~/.bashrc,然后测试:
conda --version # 应显示版本号,如 26.3.21.2 创建专用环境(避免污染 base)
conda create -n mnist_cpu python=3.11 -y
conda activate mnist_cpu1.3 安装 PyTorch(先 CPU 版本验证,后续可升级到 GPU)
CPU版本和GPU版本最好创建两个独立的python虚拟环境,分别验证。
GPU版本即CUDA版本。
在安装 PyTorch 前,首先执行 nvidia-smi 查看显卡和驱动信息(建议发给AI来确定安装什么版本的 PyTorch):
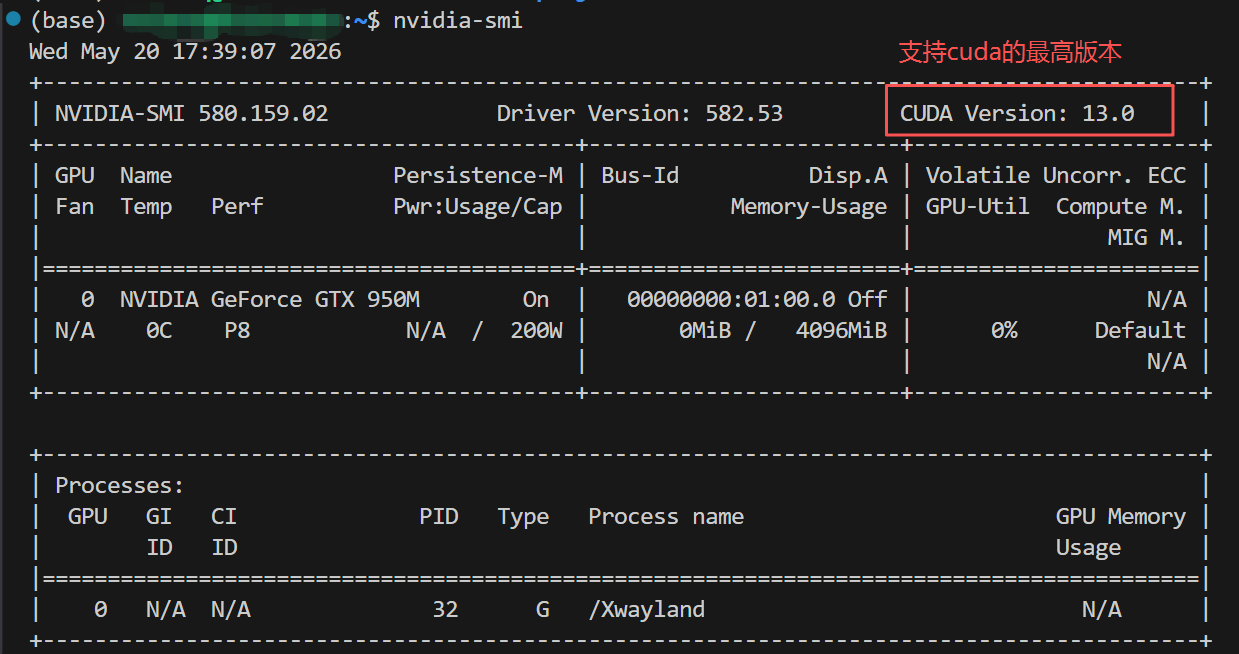
我的驱动已经升级到 582.53,支持 CUDA 13.0 及以下的所有版本,完全兼容目前所有主流 PyTorch 版本(无论使用 CUDA 11.8、12.x 还是未来更新的版本)。GTX 950M 虽然计算能力 5.0 稍老,但驱动足够新(我更新到了最新的驱动),因此可以放心使用 PyTorch 官方提供的 CUDA 12.x 预编译包,兼容性和性能都比 11.x 更好。
1.3.1 CPU 版本(仅使用 CPU 训练,不调用 GPU):
适用场景:只想快速验证代码逻辑,或暂时不想用 GPU。
特点:安装包小,无需 CUDA 驱动支持,但训练慢。
pip install torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 --index-url https://download.pytorch.org/whl/cpu1.3.2 GPU 版本(使用你的 GPU 加速,推荐)
pip install torch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 --index-url https://download.pytorch.org/whl/cu124重要:CPU 和 GPU 版本不要混装在同一个环境中。如果你先装了 CPU 版,想换 GPU 版,请先用 pip uninstall torch torchvision torchaudio 卸载,再重新安装 GPU 版。
1.4 验证安装
import torch
print(torch.__version__) # 例如 2.5.1+cpu 或 2.5.1+cu124
print(torch.cuda.is_available()) # 若安装 CPU 版本,应显示 False;若安装 GPU 版本且驱动正常,应显示 True2. PyTorch 核心组件必学
在写代码前,先快速过一遍以下核心概念(每个都将在后面的完整代码中出现)。
3. 完整实验:全连接网络在 MNIST 上分类 (建立概念即可)
3.0 快速了解(建立整体概念即可)
MNIST 是深度学习领域最经典、最基础的数据集之一,被称为“计算机视觉的 Hello World”。我要要做的事情称为“手写数字识别”,训练一个模型,实现输入一张手写数字的图片,输出图片上对应的数字。
我们先从宏观上理解一个深度学习实验的完整生命周期。整个实验可以划分为 6 个逻辑阶段,每个阶段解决一个特定问题:
训练循环的内部细节(一个 batch 经历了什么)
下图(概念图)展示了一次迭代中数据的流动过程(读者可脑补):
输入 batch (64张手写数字)
↓ [前向传播]
模型输出 logits (64×10)
↓ [损失函数]
损失值 (标量)
↓ [反向传播]
梯度 (每个参数的偏导数)
↓ [优化器更新]
更新后的模型参数关键机制说明:
前向传播:输入数据依次流过各层(线性 → ReLU → Dropout → …),最终输出 10 个类别的原始分数(logits),此时尚未转为概率。
损失计算:
CrossEntropyLoss内部自动对 logits 做LogSoftmax,然后取出正确类别的负对数概率。若模型对正确类别预测分数高,则损失小。反向传播:基于链式法则,从输出端向输入端逐层计算损失对每个参数的偏导数(梯度)。PyTorch 的自动求导机制(
.backward())自动完成这一过程。参数更新:优化器根据当前梯度及历史动量,计算出参数的变化量,加到原参数上。例如 SGD 为
W_new = W_old - lr * grad。
为什么全连接网络在 MNIST 上有效?
MNIST 手写数字尺寸小(28×28),数字居中且较规范,全连接层可以捕捉像素间的全局相关性。
三层网络(512→256→10)有约 40 万个参数,足够拟合训练集(6 万样本),Dropout 缓解了过拟合。
但全连接网络忽略了图像的局部结构(相邻像素应共享权重),因此准确率上限约 98.5%,而 LeNet-5 这种 CNN 可达 99.3% 以上。
3.1 导入所有需要的库
import torch # PyTorch 核心库,提供张量操作、自动求导等
import torch.nn as nn # 神经网络模块,包含所有层(Linear, Dropout等)
import torch.nn.functional as F # 常用函数(如 relu, softmax),不含可训练参数
import torch.optim as optim # 优化器模块,包含 Adam, SGD 等
from torchvision import datasets, transforms # torchvision 提供常用数据集和图像预处理工具
from torch.utils.data import DataLoader # 数据加载器,批量读取数据
import time # 计时,统计训练时长
import matplotlib.pyplot as plt # 绘图库,用于保存预测图片3.2 检查硬件设备(GPU/CPU)
# torch.device 用于指定计算设备
# torch.cuda.is_available() 返回 True 表示 PyTorch 检测到了 NVIDIA GPU 且驱动正常
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")
if device.type == "cuda":
# torch.cuda.get_device_name(0) 返回第0块GPU的名称
print(f"GPU 名称: {torch.cuda.get_device_name(0)}")详细解释:
torch.device("cuda") 会创建一个代表 GPU 的对象;若没有 GPU 则用 "cpu"。
后续所有张量和模型都需要 .to(device) 移动到该设备。
3.3 数据预处理与加载(Transform & DataLoader)
3.3.1 定义数据预处理流程 transform
transform = transforms.Compose([
transforms.ToTensor(), # 步骤1:将 PIL 图像或 numpy 数组转为 PyTorch 张量
transforms.Normalize((0.1307,), (0.3081,)) # 步骤2:标准化(减均值,除标准差)
])详细解释:
transforms.Compose:将多个图像变换操作组合成一个流水线,按顺序执行。transforms.ToTensor():输入:PIL Image 或 numpy 数组,取值范围 0~255(uint8)。
输出:
torch.FloatTensor,形状从(H, W, C)转为(C, H, W),并将数值缩放至[0.0, 1.0]。MNIST 是灰度图,所以形状变为
(1, 28, 28),通道数=1。
transforms.Normalize(mean, std):公式:
output = (input - mean) / std,其中mean和std可以是单个数值(对所有通道用相同值)或元组(每个通道独立)。MNIST 数据集的全局均值约为
0.1307,标准差约为0.3081。这些数值是预先计算好的(通过统计所有训练图像获得)。标准化后,数据分布将接近均值为 0、标准差为 1 的标准正态分布,有助于梯度下降更快收敛,避免梯度消失或爆炸。
3.3.2 下载并加载数据集
# 训练集:train=True,第一次运行会从网络下载到 './data' 目录
train_dataset = datasets.MNIST('./data', train=True, download=True, transform=transform)
# 测试集:train=False,同样下载/加载
test_dataset = datasets.MNIST('./data', train=False, download=True, transform=transform)参数解释:
'./data':数据存储的目录(相对路径,在当前工作目录下创建data文件夹)。train=True:加载 60000 张训练图片;train=False加载 10000 张测试图片。download=True:如果本地没有数据,则自动从官网yann.lecun.com/exdb/mnist/下载。transform:将上面定义的预处理流水线应用到每张图片上。
3.3.3 创建数据加载器 DataLoader
batch_size = 64 # 每个 mini-batch 包含 64 张图片
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)参数详解:
batch_size:一次迭代(一个 step)送入网络的样本数。太大容易超出显存,太小则梯度更新噪声大。64 是入门常见值。shuffle=True:每个 epoch 开始前打乱数据顺序,防止模型记住样本顺序(提高泛化能力)。测试集不需要打乱。DataLoader还支持num_workers(多进程加载数据),但入门保持默认 0 即可。
数据加载器的作用:
自动迭代产生批次数据,无需手动切片。
例如:
for images, labels in train_loader:,其中images.shape=(64, 1, 28, 28),labels.shape=(64,)。
3.4 定义全连接网络(MLP 类)
class MLP(nn.Module):
"""三层全连接网络,使用 ReLU 激活函数和 Dropout 正则化"""
def __init__(self):
super(MLP, self).__init__() # 必须调用父类构造函数
# 第一层全连接:输入维度 784(28*28),输出维度 512
self.fc1 = nn.Linear(28*28, 512)
# 第二层:512 → 256
self.fc2 = nn.Linear(512, 256)
# 第三层(输出层):256 → 10(对应 0-9 十个类别)
self.fc3 = nn.Linear(256, 10)
# Dropout 层:训练时以 0.2 的概率随机将部分神经元输出置为 0,防止过拟合
self.dropout = nn.Dropout(0.2)
def forward(self, x):
"""
前向传播函数,x 的形状: (batch_size, 1, 28, 28)
"""
# 步骤1:将图像展平为一维向量
# x.size(0) 获取 batch_size; -1 表示自动计算剩余维度
# 展平后形状: (batch_size, 28*28) = (batch_size, 784)
x = x.view(x.size(0), -1)
# 步骤2:第一层线性变换 + ReLU 激活 + Dropout
x = F.relu(self.fc1(x))
x = self.dropout(x)
# 步骤3:第二层线性变换 + ReLU 激活 + Dropout
x = F.relu(self.fc2(x))
x = self.dropout(x)
# 步骤4:输出层,不添加激活函数(原始 logits)
# 原因见下节损失函数的解释
x = self.fc3(x)
return x
model = MLP().to(device) # 将模型的所有参数移动到指定设备(GPU 或 CPU)
print(model) # 打印模型结构,方便检查详细解释每个组件:
nn.Module
所有神经网络的基类。你的网络必须继承它,并实现
__init__和forward。super(MLP, self).__init__()会初始化内部结构(如参数列表、训练/评估状态)。
nn.Linear(in_features, out_features)
全连接层(线性层),数学表达式:
y = x @ W.T + b,其中W是权重矩阵(shape(out, in)),b是偏置向量(shape(out,))。参数
in_features:输入特征数(对于展平后的图像就是 784)。out_features:输出特征数(隐藏层神经元个数)。可训练参数:
self.fc1.weight形状(512, 784),self.fc1.bias形状(512,)。
nn.Dropout(p)
在训练时,以概率
p随机将输入张量的某些元素置为 0,同时将剩余元素缩放1/(1-p)以保持期望不变。作用:防止神经元之间产生复杂的共适应关系,提高泛化能力。
注意:
Dropout只在训练模式(model.train())下生效;评估模式(model.eval())下自动关闭。
F.relu(x)
激活函数:
ReLU(x) = max(0, x)。非线性变换使网络能够拟合复杂函数。优点:计算简单、缓解梯度消失、带来稀疏性。
x.view(x.size(0), -1)
view是 PyTorch 中改变张量形状的方法,类似 NumPy 的reshape。x.size(0)是 batch 大小;-1表示根据总元素数量自动计算。例如输入(64,1,28,28)总元素64*1*28*28=50176,view(64, -1)会变成(64, 50176/64=784)。等价于
torch.flatten(x, start_dim=1)。
为什么输出层不加 softmax?
因为后面使用的
nn.CrossEntropyLoss内部已经组合了 LogSoftmax + NLLLoss。具体流程:CrossEntropyLoss 会对网络输出的 logits 自动应用 softmax,再计算交叉熵。
如果手动在 forward 里加
F.softmax(x, dim=1),会导致两次 softmax,破坏概率分布,造成错误结果。
3.5 定义损失函数和优化器
criterion = nn.CrossEntropyLoss() # 交叉熵损失(用于多分类)
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam 优化器nn.CrossEntropyLoss 详细解剖
公式:对于单个样本,损失 =
-log(p_target),其中p_target是模型对正确类别的预测概率。输入要求:模型输出应为 未经 softmax 的原始分数(logits),形状
(batch_size, num_classes)。内部步骤:
对 logits 应用
LogSoftmax:log_softmax_i = log( exp(x_i) / sum_j exp(x_j) )然后计算负对数似然(NLL):取正确类别对应的
log_softmax值,取负号,再求平均。
为什么这样设计?数值稳定性。直接计算 softmax 后再计算 log 容易溢出或出现
log(0)。组合起来用log_softmax更稳定。等价写法:
loss = F.nll_loss(F.log_softmax(model(x), dim=1), target)。
optim.Adam
Adam(Adaptive Moment Estimation)是目前最常用的优化器之一。
工作原理:维护每个参数的一阶矩(梯度均值)和二阶矩(梯度未中心化的方差),自适应调整学习率。
参数:
model.parameters():传入模型的所有可训练参数(weight和bias)。lr=0.001:初始学习率。Adam 对学习率不太敏感,0.001 是良好默认值。
优点:收敛快,对超参数鲁棒,适合初学者。
3.6 训练函数(每个 epoch 调用)
def train(epoch):
"""在训练集上训练一个完整的 epoch"""
model.train() # 设置为训练模式(启用 Dropout)
total_loss = 0 # 累加每个 batch 的损失
# enumerate 同时返回索引和值;batch_idx 从 0 开始
for batch_idx, (data, target) in enumerate(train_loader):
# 将数据和标签移动到指定设备(GPU/CPU)
data, target = data.to(device), target.to(device)
# 清空上一次的梯度(因为梯度会累积)
optimizer.zero_grad()
# 前向传播:输入数据,得到预测 logits
output = model(data) # output.shape = (batch_size, 10)
# 计算当前 batch 的损失值(标量)
loss = criterion(output, target)
# 反向传播:计算损失相对于模型参数的梯度
loss.backward()
# 优化器更新参数:参数 = 参数 - 学习率 * 梯度
optimizer.step()
# 累加 loss.item()(将标量张量转为 Python float)
total_loss += loss.item()
# 每 200 个 batch 打印一次进度
if batch_idx % 200 == 0:
# 已处理的样本数 = batch_idx * batch_size
processed = batch_idx * len(data)
total = len(train_loader.dataset)
percent = 100. * batch_idx / len(train_loader)
print(f'Train Epoch: {epoch} [{processed}/{total} ({percent:.0f}%)]\tLoss: {loss.item():.6f}')
# 计算当前 epoch 的平均损失
avg_loss = total_loss / len(train_loader)
print(f'====> Epoch {epoch} Average loss: {avg_loss:.4f}')每一步的详细解释:
model.train():使Dropout层生效,BatchNorm 层使用当前 batch 的统计量。必须调用,否则 Dropout 在训练时不会随机丢弃神经元。optimizer.zero_grad():PyTorch 默认梯度累积,每次反向传播前需要将旧梯度清零。不清零会导致梯度叠加,参数更新异常。loss.backward():利用自动求导机制,计算损失函数对所有requires_grad=True的张量(即模型参数)的梯度。梯度会存储在.grad属性中。optimizer.step():根据梯度更新参数。Adam 内部使用lr和梯度的一阶、二阶矩估计计算出新的参数值。loss.item():从包含单个数值的张量中提取 Python 浮点数。注意:如果后面还需要计算图(如继续反向传播),不要用.item()切断图,但这里仅用于打印,安全。
3.7 测试函数(评估模型性能)
def test():
"""在测试集上计算损失和准确率"""
model.eval() # 设置为评估模式(关闭 Dropout)
test_loss = 0
correct = 0
# 禁用梯度计算,节省显存和计算时间
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
# 累加测试损失(同样是 CrossEntropyLoss)
test_loss += criterion(output, target).item()
# 获取预测类别:沿 dim=1(类别维)取最大值索引
pred = output.argmax(dim=1, keepdim=True)
# 比较预测与真实标签,将正确预测的数量累加
# target.view_as(pred) 将 target 形状变为与 pred 相同
correct += pred.eq(target.view_as(pred)).sum().item()
# 平均损失
test_loss /= len(test_loader)
# 准确率 = 正确预测数 / 总样本数
accuracy = 100. * correct / len(test_loader.dataset)
print(f'Test set: Average loss: {test_loss:.4f}, Accuracy: {correct}/{len(test_loader.dataset)} ({accuracy:.2f}%)\n')
return accuracy关键点详解:
model.eval():关闭 Dropout,使所有神经元都参与计算(不再随机丢弃)。同时如果网络中有 BatchNorm,它会使用训练阶段统计的全局均值和方差。with torch.no_grad()::上下文管理器,其内部的代码不会被记录到计算图中,从而不保存中间变量的梯度。这能大幅降低显存占用,并加快前向传播速度。output.argmax(dim=1, keepdim=True):argmax返回最大值索引。dim=1表示在类别维度(10个输出)上找最大值。keepdim=True保持维度数量,例如从(64,10)→(64,1),方便后续比较。
pred.eq(target.view_as(pred)):target原始形状(64,),view_as(pred)将其变为(64,1),形状匹配后逐元素比较。返回布尔张量,例如
[[True], [False], ...]。.sum().item()统计 True 的个数(True 计为 1,False 为 0)。
3.8 训练循环并保存最佳模型
epochs = 10 # 迭代训练集 10 次
best_acc = 0 # 记录到目前为止的最高准确率
start_time = time.time()
for epoch in range(1, epochs + 1):
train(epoch) # 完成一个 epoch 的训练
acc = test() # 在测试集上评估
# 如果当前模型准确率更高,则保存
if acc > best_acc:
best_acc = acc
# torch.save 可以保存任何 Python 对象,这里保存模型的 state_dict(参数字典)
torch.save(model.state_dict(), 'best_mnist_mlp.pth')
print(f"保存新最佳模型,准确率: {acc:.2f}%")
end_time = time.time()
print(f"训练完成,总耗时: {end_time - start_time:.2f} 秒,最佳准确率: {best_acc:.2f}%")详解:
model.state_dict():返回一个字典,将每个层参数名(如'fc1.weight')映射到其张量值。这是推荐的保存方式,只包含参数,不包含代码结构,跨平台兼容性好。保存的文件
'best_mnist_mlp.pth'可以随后用model.load_state_dict(torch.load(...))恢复。epochs=10:对于 MNIST,10 轮通常已经足够收敛。更多轮数可能过拟合,但 MLP 不易过拟合严重,10~20 皆可。
3.9 加载模型并对单张图片预测 + 保存结果图
# 加载之前保存的最佳模型参数
# weights_only=False 是为了避免安全性警告(因为是你自己训练的模型)
model.load_state_dict(torch.load('best_mnist_mlp.pth', map_location=device, weights_only=False))
model.eval() # 切换到评估模式
# 取测试集中的第一个 batch
test_iter = iter(test_loader) # 将 DataLoader 转换为迭代器
images, labels = next(test_iter) # 获取第一个 batch:images 形状 (64,1,28,28)
# 取出 batch 中的第一张图片,并增加 batch 维度
img = images[0].unsqueeze(0).to(device) # unsqueeze(0) 在第0维增加一维,形状变 (1,1,28,28)
true_label = labels[0].item() # 真实标签
# 预测
with torch.no_grad():
output = model(img) # 输出 logits,形状 (1,10)
pred = output.argmax(dim=1).item() # 取最大值索引,得到预测数字
print(f"单张图片预测结果: 预测值 = {pred}, 真实标签 = {true_label}")
# 使用 matplotlib 保存图片(不弹出窗口)
fig, ax = plt.subplots() # 创建图形和坐标轴
ax.imshow(images[0].squeeze(), cmap='gray') # .squeeze() 移除尺寸为1的维度 (1,28,28) -> (28,28)
ax.set_title(f'Predicted: {pred}, True: {true_label}')
fig.savefig('mnist_prediction.png', dpi=150, bbox_inches='tight') # 保存为 PNG
print(f"预测图片已保存至当前目录下的 'mnist_prediction.png'")
plt.close(fig) # 关闭图形,释放内存详细介绍:
torch.load加载时指定map_location=device,确保将张量加载到正确的设备(即使模型是在 GPU 上保存的,加载到 CPU 也需映射)。weights_only=False:PyTorch 2.x 开始默认安全模式为True,但加载自己训练的文件不会有风险,显式设为False可避免警告。unsqueeze(0):因为模型期望输入是 4 维(batch, channels, height, width),单张图片只有 3 维,增加 batch 维度。plt.subplots():返回(fig, ax),其中fig是整个画布,ax是坐标系对象。imshow:显示灰度图,参数cmap='gray'使用灰度颜色映射。savefig:dpi=150控制分辨率,bbox_inches='tight'裁剪掉多余的空白区域。plt.close(fig):防止在脚本或交互式环境中累积大量图片对象导致内存泄漏。
3.10 完整代码
以下是将上述所有部分整合后的完整代码,可直接保存为 .py 文件运行。
"""
PyTorch 入门实验:MNIST 手写数字分类(全连接网络)
环境:Ubuntu + PyTorch 2.5.1 + Python 3.11 + CUDA 12.x
作者:TalentQ
日期:2026-05-21
说明:本代码包含环境检查、数据加载、模型定义、训练、测试、模型保存、单张预测及结果保存。
每行代码都有详细注释,适合零基础学习者。
"""
# ========================== 1. 导入必要的库 ==========================
import torch # PyTorch 主库:张量、自动求导
import torch.nn as nn # 神经网络层(Linear, Dropout等)
import torch.nn.functional as F # 激活函数、损失函数等(不含参数)
import torch.optim as optim # 优化器(Adam, SGD等)
from torchvision import datasets, transforms # 数据集与图像预处理
from torch.utils.data import DataLoader # 数据批量加载器
import time # 计算训练耗时
import matplotlib.pyplot as plt # 保存预测图片
# ========================== 2. 检查 GPU 可用性 ==========================
# torch.device 对象,表示计算设备(CPU 或 CUDA GPU)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")
if device.type == "cuda":
print(f"GPU 名称: {torch.cuda.get_device_name(0)}")
# ========================== 3. 数据预处理与加载 ==========================
# 定义图像变换流水线:转为张量 → 标准化
transform = transforms.Compose([
transforms.ToTensor(), # 将 PIL Image 或 numpy 数组转为 Tensor,并缩放到 [0, 1]
transforms.Normalize((0.1307,), (0.3081,)) # 标准化:减均值除标准差,加速收敛
])
# 下载 MNIST 训练集(60000张)和测试集(10000张),并应用上述变换
train_dataset = datasets.MNIST('./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST('./data', train=False, download=True, transform=transform)
# 批次大小:每次迭代送入网络 64 张图片
batch_size = 64
# 训练加载器:打乱顺序,每个 epoch 重新洗牌
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# 测试加载器:不需要打乱
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# ========================== 4. 定义全连接神经网络模型 ==========================
class MLP(nn.Module):
"""三层全连接网络,使用 ReLU 激活和 Dropout 正则化"""
def __init__(self):
super(MLP, self).__init__()
# fc1: 输入 784 (28*28) -> 输出 512
self.fc1 = nn.Linear(28*28, 512)
# fc2: 512 -> 256
self.fc2 = nn.Linear(512, 256)
# fc3: 256 -> 10 (0-9 十个类别)
self.fc3 = nn.Linear(256, 10)
# Dropout 层: 训练时随机丢弃 20% 的神经元,防止过拟合
self.dropout = nn.Dropout(0.2)
def forward(self, x):
"""
前向传播
x 形状: (batch_size, 1, 28, 28)
"""
# 步骤1:展平。将每个图像从 (1,28,28) 变成 (784,)
x = x.view(x.size(0), -1) # x.size(0) = batch_size, -1 自动计算剩余维度
# 步骤2:第一层 -> ReLU -> Dropout
x = F.relu(self.fc1(x))
x = self.dropout(x)
# 步骤3:第二层 -> ReLU -> Dropout
x = F.relu(self.fc2(x))
x = self.dropout(x)
# 步骤4:输出层,返回 logits(未经过 softmax)
x = self.fc3(x)
return x
# 实例化模型,并移动到指定设备(GPU 或 CPU)
model = MLP().to(device)
print(model) # 打印模型结构,便于检查
# ========================== 5. 定义损失函数和优化器 ==========================
# 交叉熵损失:内部组合了 LogSoftmax + NLLLoss,接受原始 logits 作为输入
criterion = nn.CrossEntropyLoss()
# Adam 优化器:自适应学习率,传入模型参数和初始学习率
optimizer = optim.Adam(model.parameters(), lr=0.001)
# ========================== 6. 训练函数 ==========================
def train(epoch):
"""在一个完整 epoch 上训练模型"""
model.train() # 设置为训练模式(启用 Dropout)
total_loss = 0 # 累计该 epoch 所有 batch 的损失
# 遍历训练数据加载器
for batch_idx, (data, target) in enumerate(train_loader):
# 将数据移动到设备(GPU/CPU)
data, target = data.to(device), target.to(device)
# 清零梯度(因为梯度会累积)
optimizer.zero_grad()
# 前向传播:计算预测 logits
output = model(data) # output shape: (batch_size, 10)
# 计算损失
loss = criterion(output, target) # 标量张量
# 反向传播:计算梯度
loss.backward()
# 更新参数
optimizer.step()
# 累加损失值(.item() 将张量转为 Python 浮点数)
total_loss += loss.item()
# 每 200 个 batch 打印一次进度
if batch_idx % 200 == 0:
processed = batch_idx * len(data) # 已处理样本数
total = len(train_loader.dataset) # 总样本数
percent = 100. * batch_idx / len(train_loader)
print(f'Train Epoch: {epoch} [{processed}/{total} ({percent:.0f}%)]\tLoss: {loss.item():.6f}')
avg_loss = total_loss / len(train_loader)
print(f'====> Epoch {epoch} Average loss: {avg_loss:.4f}')
# ========================== 7. 测试函数 ==========================
def test():
"""在测试集上评估模型,返回准确率"""
model.eval() # 设置为评估模式(关闭 Dropout)
test_loss = 0
correct = 0
# 禁用梯度计算(节省内存和计算)
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
# 累加测试损失
test_loss += criterion(output, target).item()
# 获取预测类别:沿维度 1 取最大值索引
pred = output.argmax(dim=1, keepdim=True)
# 统计正确预测数
correct += pred.eq(target.view_as(pred)).sum().item()
# 平均损失
test_loss /= len(test_loader)
# 准确率 = 正确数 / 总样本数 * 100%
accuracy = 100. * correct / len(test_loader.dataset)
print(f'Test set: Average loss: {test_loss:.4f}, Accuracy: {correct}/{len(test_loader.dataset)} ({accuracy:.2f}%)\n')
return accuracy
# ========================== 8. 训练循环并保存最佳模型 ==========================
epochs = 10 # 训练轮数
best_acc = 0 # 最佳准确率初始为 0
start_time = time.time() # 记录开始时间
for epoch in range(1, epochs + 1):
train(epoch) # 训练一个 epoch
acc = test() # 测试当前模型
# 如果当前准确率优于历史最佳,则保存模型参数
if acc > best_acc:
best_acc = acc
# 保存 state_dict(参数字典)到文件
torch.save(model.state_dict(), 'best_mnist_mlp.pth')
print(f"保存新最佳模型,准确率: {acc:.2f}%")
end_time = time.time()
print(f"训练完成,总耗时: {end_time - start_time:.2f} 秒,最佳准确率: {best_acc:.2f}%")
# ========================== 9. 加载最佳模型并对单张图片预测 ==========================
# 从文件加载模型参数(映射到当前设备,并关闭安全检查)
model.load_state_dict(torch.load('best_mnist_mlp.pth', map_location=device, weights_only=False))
model.eval() # 评估模式
# 取测试集中的第一个 batch
test_iter = iter(test_loader)
images, labels = next(test_iter) # images: (64,1,28,28), labels: (64,)
# 取该 batch 中的第一张图片,并增加 batch 维度
img = images[0].unsqueeze(0).to(device) # 形状变为 (1,1,28,28)
true_label = labels[0].item() # 真实标签(0-9)
# 预测
with torch.no_grad():
output = model(img) # (1,10)
pred = output.argmax(dim=1).item() # 预测数字
print(f"单张图片预测结果: 预测值 = {pred}, 真实标签 = {true_label}")
# ========================== 10. 保存预测图片(不弹窗) ==========================
fig, ax = plt.subplots() # 创建画布和坐标轴
ax.imshow(images[0].squeeze(), cmap='gray') # squeeze 去掉单通道维度 (28,28)
ax.set_title(f'Predicted: {pred}, True: {true_label}')
fig.savefig('mnist_prediction.png', dpi=150, bbox_inches='tight') # 保存为 PNG
print("预测图片已保存至当前目录下的 'mnist_prediction.png'")
plt.close(fig) # 关闭图形,释放资源3.11 实验结果与讨论
预期准确率:95% ~ 98%(MLP 在 MNIST 上的上限约为 98.5%)。
训练时间:训练 10 个 epoch,GTX 950M 上约 30 秒,纯 CPU 约 2~3 分钟。
为什么准确率不是 100%:全连接网络缺乏平移不变性,对图像局部结构不敏感。CNN 可轻松超过 99%。
下一步建议:
尝试调整网络结构(增加/减少层数、改变 Dropout 比例)。
使用 TensorBoard 可视化损失曲线。
进入 CNN 实验,在 CIFAR-10 数据集上实现卷积神经网络。
评论区